disk에 있는 simple index를 main memory를 올려서 사용하면 search에 대한 cost가 cpu cost이기 때문에 적다.
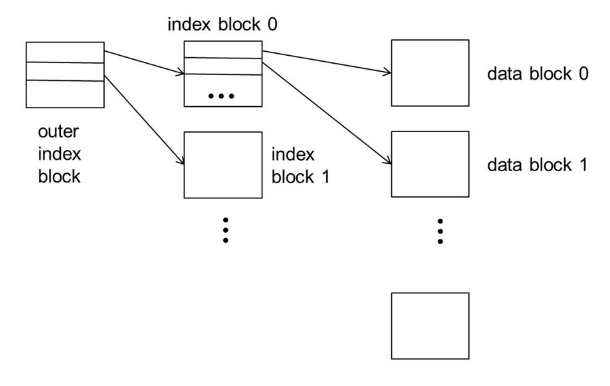
하지만, data file이 매우 크게 되면 simple index를 main memory에 올리기 어렵다. 그러면 구조를 바꿔서 simple index에 대한 sparse index를 만들어 main memory에 올려서 사용하면 된다.
sparse index에서는 블락에 대한 가장 작은 키 값을 index 키로 해서 만들 수 있다.
index update: deletion in data file

dense index인 경우
data file에서 delete가 발생하면 dense index에서도 지워야 한다.
sparse index인 경우
위 사진처럼 sparse index라면 영향을 받지 않아서 변경되는 것이 없다. 101을 record를 삭제했을 때는 index에서 101을 102로 바꿔주면 된다. 데이터파일에서 102도 삭제하면 어떻게 될까? 105로 업데이트해야하는데 이미 index에 있으므로 index 파일의 102레코드를 삭제해주면 된다.
index update: insertion in data file
dense index인 경우
index에도 동일하게 추가하고 sort해주면 된다.
sparse index인 경우
103이 추가될 때 데이터 파일의 101,102가 들어갈 블락과 같으면 index는 영향을 받지 않는다. 하지만, 103이 추가될 때 새로운 블락을 잡아서 저장해야한다면 index에 추가해야한다.
secondary index
항상 dense해야 한다. secondary에 대해서는 data가 정렬되어 있지 않기 때문에 dense를 써야한다.

salary라는 key에 대해서 secondary index를 만들었다. 이 키에 여러 개의 record가 있을 수 있기 때문에 중간에 bucket을 두어 여러 개를 포인팅 하도록 하였다.
primary vs secondary
두 방식 다 index를 여러 개 둘 수 있는데 update에 대한 오버헤드가 많으므로 주의해야 한다.
sequential scan
- primary is efficient, 같은 순서대로 정렬되어 있으므로 물리적으로 인접한 데이터를 사용하면 seek비용이 적기 때문에 cost가 적다.
-secondary is expensive, 인덱스를 통해 접근하는 것이 random하게 읽는 방식이어서 seek비용이 크다. 따라서 secondary index를 사용해서 sequential하게 읽으면 비효율적이다.
'컴퓨터공학 > 데이터베이스(database)' 카테고리의 다른 글
| [Indexing]B+ tree insertion (0) | 2020.06.05 |
|---|---|
| [Indexing]B+ tree index (0) | 2020.06.05 |
| [Indexing]Overview (0) | 2020.06.05 |
| [Storage Device]File Organization (0) | 2020.06.05 |
| [Storage Device]RAID (0) | 2020.06.05 |



