simple index 사이즈가 커지게 되면 메인 메모리에 올리기 어려워서 비효율적이다. 그렇기 떄문에 b+ tree나 hashing을 쓰게 된다.
학생 테이블이 있을 때 학번에 대해서 검색이 자주 일어나면 미리 학번에 대한 b+ tree를 disk에 만들어두고 사용할 수 있다. 이에 대한 hash file을 만들어 두어도 된다.
B tree family = B tree, B+ tree, B* tree
가장 장점이 많은 트리가 B+ tree이고 가장 널리 사용된다. insert, delete 될 때 변화가 지역적으로 발생하는 것이 장점이다. simple index의 장점은 메인 메모리에 로드해서 사용할 수 있는데 크기가 커지면 그 비용이 커진다. 따라서 B+ tree가 대안이 될 수 있다.
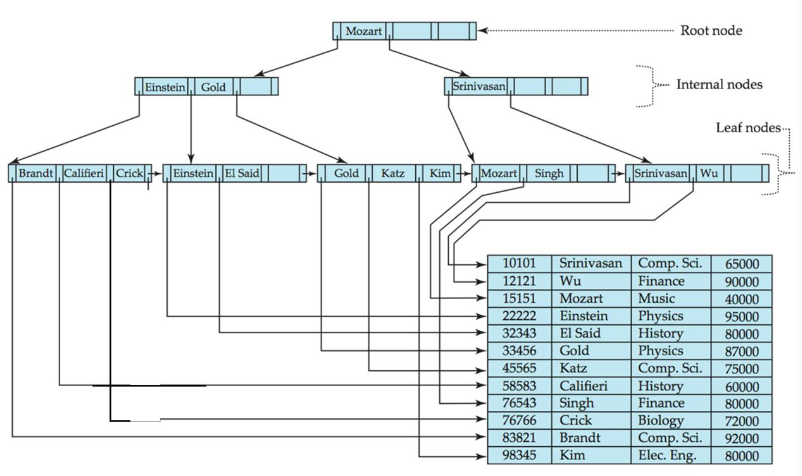
B+ tree와 data file의 logical view이다. 실제로는 page단위로 저장이 되어 있다. b+에서의 b는 balanced라는 말이 있다.
b+ tree 특징
bst와 구조가 비슷하다.
balanced해서 leaf 노드까지의 길이가 같다.
bst에 비해 depth가 작다.
node 하나 당 한 개의 페이지를 할당한다. node = n개의 pointer + n-1개의 key
B+ tree 만족조건
non leaf node : C(2/n) ~ n개의 point 를 가져야한다.(C=Ceiling)
leaf node: C((n-1)/2) ~ n-1개의 key를 가져야 한다.
root
-root가 leaf일 때 0~n-1개의 키를 가져야 한다.
-root가 non-leaf일 때 최소 2개의 child를 가져야 한다.

k= key
p = pointer ( non-leaf이면 child의 address이고 leaf 이면 data record의 address)
k1 < k2 < k3 < .. < kn-1
key끼리 중복이 없다.

결국 B+ tree의 최종적 역할은 key를 가지고 검색을 하면 key에 대한 유무를 알려주어야 한다. leaf에 key가 존재한다면 해당 record의 pointer를 알려주어야 한다. 위의 모습은 logical한 모습이고 page단위로 저장될 경우에 pointer의 값은 non-leaf의 경우에는 page#이고 leaf의 경우에는 page#, offset for record이다.
Pn은 next leaf node를 pointing한다.
non-leaf node는 각 leaf노드를 대표하는 값들을 가진다. 즉, sparse index이어서 child 노드를 구분할 수 있도록 대표적인 값을 취한다 . non-leaf node는 multi-level sparse index이다.
p1을 따라가면 서브트리를 만나게 되고 서브트리의 모든 키 값들은 k1보다 작은 것들만 존재한다.
p2를 따라가면 서브트리가 있고 k1<= 서브트리 모든 키 값 < k2이다.
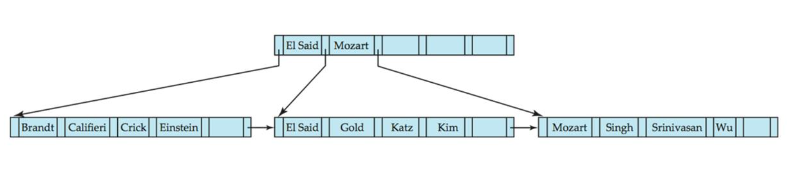
B+ tree(n=6) : 모든 노드가 가질 수 있는 최대 포인터의 개수가 6개 이다.
leaf nodes: 공식에 따라 키의 개수가 3개 이상 5개 이하여야 한다.
non-leaf nodes: 공식에 따라 child 개수가 3~ 6개이어야 한다.
non-leaf root: 최소 2개의 child
B+ tree maximum Height
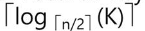
maximum lookup

index entry: p1,k1 과 같이 한 pair을 index entry라 한다.
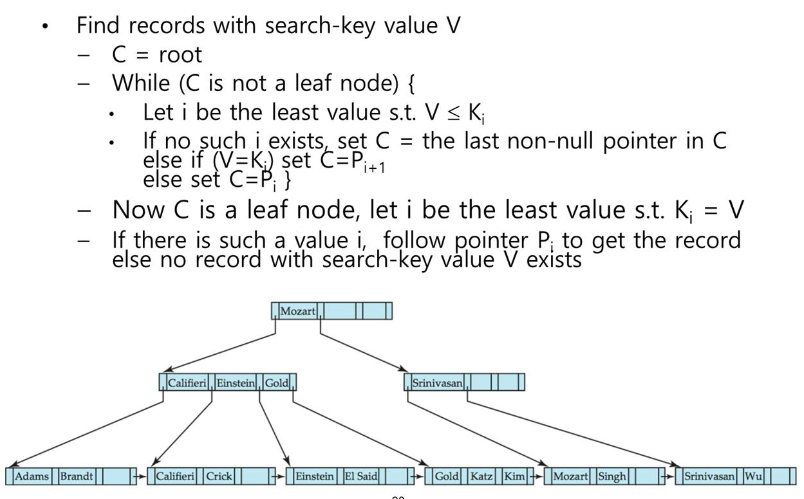
교수 이름이 "kim" 일 때 동작하는 방식
root 노드가 저장된 page를 main memory에 올려서 key, pointer를 살펴본다. 어떤 포인터를 따라가야 하는지 파악한다. "Mozart" 보다 "Kim"이 작기 때문에 왼쪽 포인터를 따라간다. 즉, root node의 page에 저장된 pointer 정보를 사용하여 left child의 page를 찾아간다.
child로 가서 키 값을 살펴보면 gold 보다 kim이 크기 때문에 gold의 오른쪽 pointer를 따라간다.
pointer가 가리키는 노드가 leaf에 해당하기 때문에 kim이 있는지 파악한다. kim이 있기 때문에 해당 record의 주소 값을 leaf node의 page에서 얻어낸다.
page단위로 저장하는 방식이라면 pointer 정보를 통해 page#와 offset을 얻게 된다. 3개의 page(노드) 만을 읽어서 record의 위치를 알아냈다.
'컴퓨터공학 > 데이터베이스(database)' 카테고리의 다른 글
| [Indexing]B+ tree deletion (0) | 2020.06.05 |
|---|---|
| [Indexing]B+ tree insertion (0) | 2020.06.05 |
| [Indexing]Multilevel index (0) | 2020.06.05 |
| [Indexing]Overview (0) | 2020.06.05 |
| [Storage Device]File Organization (0) | 2020.06.05 |



