중복된 key 값이 존재한다면 어떻게 해야할까? 이전에 simple index에서 bucket을 살펴보았다. leaf노드와 record 중간에 bucket을 두는 것을 고려할 수 있다. 아니면, 중복되는 키 값을 허용할 수도 있다. k1 <= k2 <= ... <= kn-1의 조건으로 두는 것이다.
non-unique key가 존재하면 deletion할 때 비용이 비싸진다. key에 record id를 붙여서 저장하면 unique해진다.
B+ tree variation
B+ tree 구조에서는 data가 따로 존재했는데 table을 없애버리고 record를 leaf노드에 저장할 수 있다. leaf node에 최대한 많은 record를 저장하여 공간 낭비를 줄일 수 있다.
이런 구조 하에서는 simple index와 hash table이 가리킬 record가 leaf노드가 된다. 이 때, insert, delete로 인해 b+ tree 구조가 바뀌게 되면 관련된 addr들을 다 업데이트 해주어야한다. 이는 비용이 크기 때문에 primary index를 만들어 두는 것을 고려할 수 있다.
indexing string issue
key length가 크면 leaf에 저장될 수 있는 key의 수가 줄어드므로 depth가 커진다. depth를 최대한 안 늘리려면 key의 앞부분 일부만을 써서 키의 길이를 줄이는 것을 고려할 수 있다.
bulk loading
b+ tree를 새로 만들 때 record가 많으면 disk io비용이 크다. 이를 위한 방안은 두 가지 이다.
1. key에 대해 소팅을 하고 난 후 insert를 한다. 이것의 문제는 leaf 노드의 반 정도만을 사용해 depth가 커진다.
2. bottom-up b+ trree construction
1방식에서 leaf를 다 채우는 방법이다. 우선 key에 대해 소팅한다. leaf에서 n개 키를 저장할 수 있으면 소팅된 키를 n개씩 묶어서 leaf노드를 먼저 만든다. 이후 leaf가 최대 child 개수가 되면 부모 노드 하나로 묶는다. 이런 방식으로 leaf 부터 full로 채워서 B+ tree를 완성한다.
b tree index
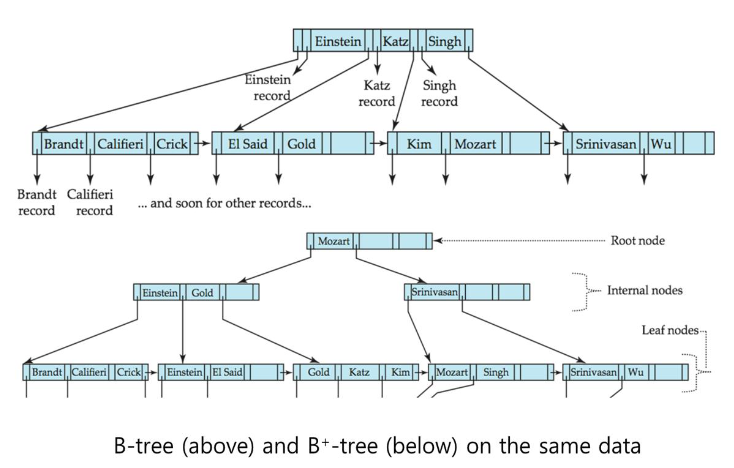
b tree는 non-leaf node에도 record에 대한 포인터를 갖고 있는다. b+ tree는 탐색을 위해 leaf까지 가야하지만 b tree는 항상 leaf까지 가는 것은 아니다. search시에 performance가 좋아질 수 있다. b tree는 non-leaf node가 leaf node와 구조가 다르므로 insert, delete할 시에 비용이 많이 들 수 있고 구조가 복잡하다.
순차적 탐색을 하고 싶을 때 b+ tree에서는 leaf node만을 가지고 탐색할 수 있는데 b tree는 그렇지 않다.
따라서, b+ tree가 장점이 더 많고 현실에서는 b+ tree를 사용한다.
multiple attribute
where 절에 deptname ='cs' and salary = 8000; 이 있으면 각각의 attribute에 대한 b+ tree에서 record set을 구해서 교집합을 구하면 될 것이다. 혹은, (deptname, salary)에 대한 b+ tree를 만들어 둘 수도 있다.
'컴퓨터공학 > 데이터베이스(database)' 카테고리의 다른 글
| [Indexing]Dynamic Hashing (0) | 2020.06.06 |
|---|---|
| [Indexing]Static Hashing (0) | 2020.06.06 |
| [Indexing]B+ tree deletion (0) | 2020.06.05 |
| [Indexing]B+ tree insertion (0) | 2020.06.05 |
| [Indexing]B+ tree index (0) | 2020.06.05 |



