query를 처리하는 방법에 대해서 살펴본다.
subtopic
overview
selection operation
sorting
join
overview
user
l
(app)
l
DBMS
l
record table + indecies( B+tree hash-table simple-index) + catalog
위와 같은 구조로 구성되며 DBMS는 query를 입력으로 받아서 여러 개의 plan 중에서 제일 비용이 적은 plan을 결정한다. 비용은 catalog의 질의를 위한 통계 데이터를 활용하여 계산할 수 있다.
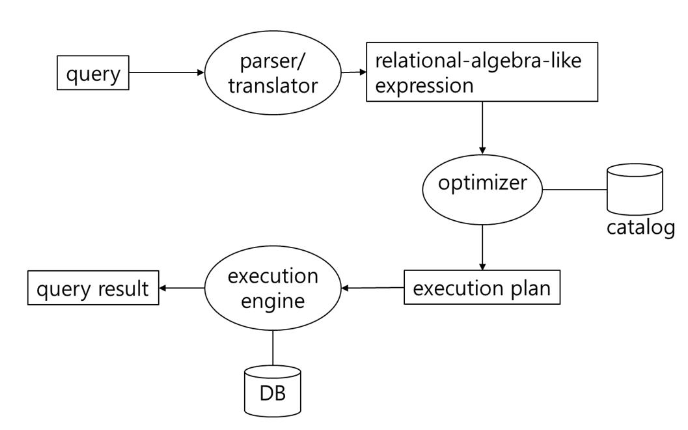
query가 처리되는 과정이다. 네모는 input/output이고 타원은 action이다.
parser/translator: syntax, semantic을 확인하고 관계대수로 변환한다.
optimizer: catalog 정보를 활용해 비용을 계산해서 가장 최적의 plan을 찾아낸다.
execution engine: plan을 처리 방식에 따라 처리한다. 이 때 필요한 데이터들은 db에서 io한다.
query optimization 과정에서 비용을 정확하게 계산하기 때문에 아주 중요한 작업이다. 하나의 query를 여러 개의 관계대수로 표현할 수 있다. 하나의 관계 대수를 처리하는 방식이 여러 가지가 가능하다.
operation에 대한 cost를 계산할 때 통계 데이터(recored #, size of record, data distribution)를 사용한다.
select salary
from professor
where salary < 7000
이 query를 수행하는 plan중에 하나는 다음과 같다.

professor table을 가지고 와서 index file을 활용하라는 플랜이다.
query cost: cost는 disk i/o이 대부분이고 cpu, network io 도 있다.
disk i/o type
number of seeks
number of blocks read
number of blocks written
write block > read block

B개의 block을 읽고 S번의 seek가 있는 경우이다. seek가 transfer보다 비싸다. seek가 비싸기 때문에 관련있는 데이터는 최대한 가까운 page에 저장하여 가까운 실린더에 있도록 해야한다.
join을 하다보면 중간 결과가 존재하는데 크기가 크지 않으면 main memory에 유지한다. 중간 결과의 테이블이 크면 disk에 저장해야 해서 disk io 비용이 발생한다.
buffering effect
table을 읽어야하는데 buffer에 존재하는 경우엔 disk io cost를 절약할 수 있다. 하지만, buffer에 항상 데이터가 있는 것은 아니기 때문에 buffering effect은 비용 계산시 고려하지 않는다.
'컴퓨터공학 > 데이터베이스(database)' 카테고리의 다른 글
| [Query Processing]Sorting (0) | 2020.06.07 |
|---|---|
| [Query Processing]Selection Operation (0) | 2020.06.06 |
| [Indexing]Bitmap Index (0) | 2020.06.06 |
| [Indexing]Dynamic Hashing (0) | 2020.06.06 |
| [Indexing]Static Hashing (0) | 2020.06.06 |


