mainmemory에 올려서 정렬할 수 있는 것을 internal sort
external sort의 경우는 disk의 table을 main memory에 올릴 수 있는 크기로 나누어서 internal sort를 하고 file로 저장한다. 이렇게 저장된 것을 run이라고 하며 run들을 merge를 하게 되면 특정한 칼럼에 대해 정렬할 수 있다.
external sort-merge
main memory 크기는 M개의 page가 존재할 수 있음. page=block이라고 본다.
1.m개의 block을 읽어서
2.소팅한 후
3.run을 저장한다.
4.n 개의 run이 주어졌을 때 merge한다.
1~4의 결과 다음과 같은 결과가 된다.
run1(multiple page) run2 run3 ... runN
N< M 일 때
N개의 run에서 첫번째 block를 읽어서 sort한 후 한 page씩 저장한다.
buffer를 input buffer(M-1개 page), output buffer(1개 page)로 둔다. output buffer는 꽉 찼을 때 sorted table에 write한다.
N>=M 일 때
input(M-1) output(1) --> main memory
run(N) ---> disk
이렇게 만들면 N개의 run에서 1개의 page씩 읽으면 main memory size보다 커진다. 따라서 N개의 run대신 M-1이하인 run을 여러 개 만든다.
run(M-1) run(M-1) run(M-3) 과 같이 말이다. 각 run마다 sort하고 나서 저장한다. 그러면 run(1) run(1) run(1)이 된다. run의 size가 커지게 되지만 run의 개수 자체는 줄어든다. 이 과정을 반복하면서 run의 개수가 M보다 작아질 때 까지 반복한다.

가정. 하나의 페이지에 하나의 튜플이다.
가정. 버퍼 사이즈는 3개의 페이지
가정. 2개의 페이지는 인풋 버퍼, 1개의 페이지는 아웃풋 버퍼.
3개씩 읽어서 run을 만든다. 총 4개의 run을 만든 것을 알 수 있다. run에 대하여 N(4) < M(3)이 만족하지 않는다.
따라서 run을 합친다. run을 합친다는 것은 2개의 run에 대해서 sorted table을 만드는 작업과 같다. 즉, a,d,l이 있는 run과 b,c,e가 있는 run이 있다. a-17, b-15가 각 run에서 가장 작은 레코드이므로 메모리로 읽는다. a < b이므로 a-17을 sorted table에 쓴다. 이후 a-17이 있던 run에서 다음 레코드인 d-12를 메모리로 읽는다. d >b 이므로 b-15를 write 한다. 다음은 b-15가 있던 run에서 c-33을 꺼내고. 이 과정을 반복하게 되면 sorted table이자 run인 table이 하나 만들어진다. 동일하게 아래 run들에 대해서도 진행하면 6개의 레코드가 있는 run이 2개 만들어진다. N(2)< M(3)이므로 external sort를 하면 결과 table이 만들어진다.
하지만 질의가 '학생 이름 순서대로 출력하시오.'라면 마지막 merge에서 output buffer의 데이터를 disk에 write할 필요는 없다.
계산
초기 run의 개수는 br/ M (br = # of blocks containing records = 블락에 있는 레코드 수, M= 메모리의 블락의 수) 위의 예제에서는 12/3 = 4
merge pass #
결국에는 B+ tree와 연관지어 보면 총 pass의 횟수는 depth라고 볼 수 있다.
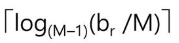
초기 run을 만들 때 블락 trasfer 값은 초기 테이블의 블락의 수 x 2가 된다.(전부 다 읽고 전부 다 쓰기 때문에 block을 br개 읽고 br개 write함).
초기 run 만들 때 block transfer = 2 * br
merge pass에서도 전부 다 읽고 전부 다 써야하기 때문에 2*br의 block transfer가 필요하다.
merge pass까지 block transfer # = 2 * br *#passes
최종에 파일로 만들지 않을 경우 br번은 절약된다.
정리하면 total # of block transfer = 2br + (2br *pass #) - br*(최종 결과를 파일로 쓰는지 여부)
cost of seeks
during creating initial run
초기 run을 만들 때 최악의 경우 읽는 것C(br/M)번, 쓰는 것 C(br/M)번 (C= Ceiling)
2(br/M)
during merge phase
가정. bb = 읽고 쓸 때 run에서 읽는 블락의 수
이후 run에서 읽을 때 C(br/bb)번, 쓸 때 C(br/bb)번 이다. 왜냐하면 쓰기를 한 번에 하는게 아니라 읽는것과 쓰는것을 번갈아서 하기 때문이다.
2C(br/bb)
total # of seeks
2C(br/M) + 2C(br/bb) *merge pass
여기서 최종 파일을 디스크에 쓰지 않는다면 C(br/bb)를 빼준다.
'컴퓨터공학 > 데이터베이스(database)' 카테고리의 다른 글
| database table join (0) | 2024.05.14 |
|---|---|
| [Query Processing]Join Operation (0) | 2020.06.07 |
| [Query Processing]Selection Operation (0) | 2020.06.06 |
| [Query Processing]Overview (0) | 2020.06.06 |
| [Indexing]Bitmap Index (0) | 2020.06.06 |


